PandaWiki -一款 AI 大模型驱动的开源知识库系统
近期再网上瞎逛,发现一个新的本地构建的知识库系统,PandaWiki 。
PandaWiki 是一款 AI 大模型驱动的开源知识库搭建系统,帮助你快速构建智能化的 产品文档、技术文档、FAQ、博客系统,借助大模型的力量为你提供 AI 创作、AI 问答、AI 搜索等能力。
🔥 功能与特色
-
- 强大的富文本编辑能力:兼容 Markdown 和 HTML,支持导出为 word、pdf、markdown 等多种格式。
-
- AI 驱动智能化:AI 辅助创作、AI 辅助问答、AI 辅助搜索。
-
- 轻松与第三方应用进行集成:支持做成网页挂件挂在其他网站上,支持做成钉钉、飞书、企业微信等聊天机器人。
-
- 通过第三方来源导入内容:根据网页 URL 导入、通过网站 Sitemap 导入、通过 RSS 订阅、通过离线文件导入等。
既然如此,那本地构建试试。
系统环境
-
- 操作系统:Linux
-
- CPU 指令架构:x86_64
-
- 软件依赖:Docker 20.10.14 版本以上
-
- 软件依赖:Docker Compose 2.0.0 版本以上
-
- 推荐资源:1 核 CPU / 4 GB 内存 / 20 GB 磁盘
-
- 最低资源:1 核 CPU / 2 GB 内存 / 5 GB 磁盘
测试开始
构建基础硬件环境(基于虚拟机环境构建)
硬件
构建符合环境的硬件配置
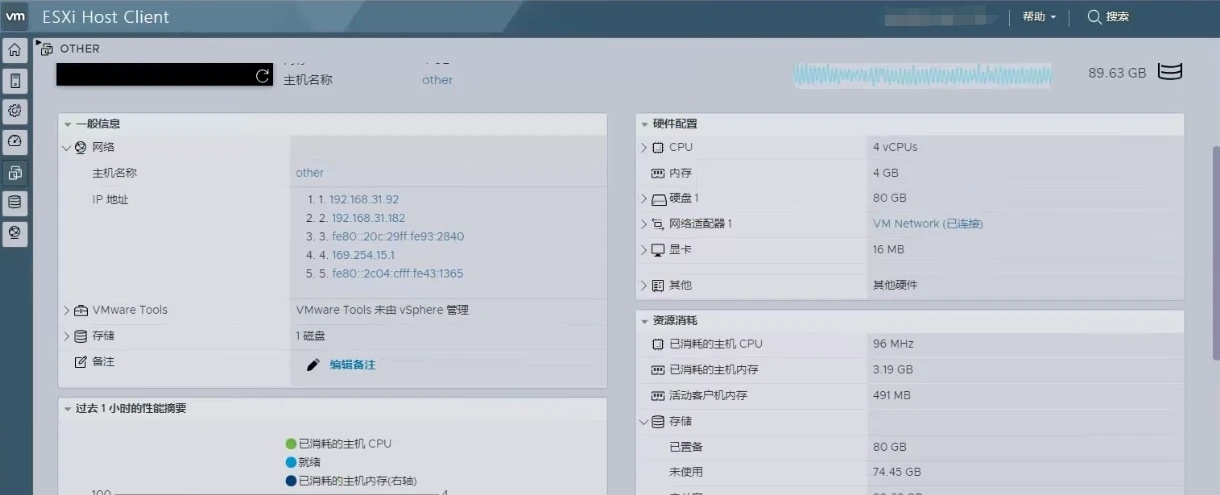
软件
配置Docker 环境,这里直接使用LinuxMirrors的一键脚本,全程按提示操作
bash <(curl -sSL https://linuxmirrors.cn/docker.sh)了解更多信息,请访问官方网站:https://linuxmirrors.cn
配置好后,安装 PandaWiki,
使用 root 权限登录你的服务器,然后执行以下命令,嗯,升级卸载都用它。
bash -c "$(curl -fsSLk https://release.baizhi.cloud/panda-wiki/manager.sh)"
选择【安装】即可。
完成后如下,
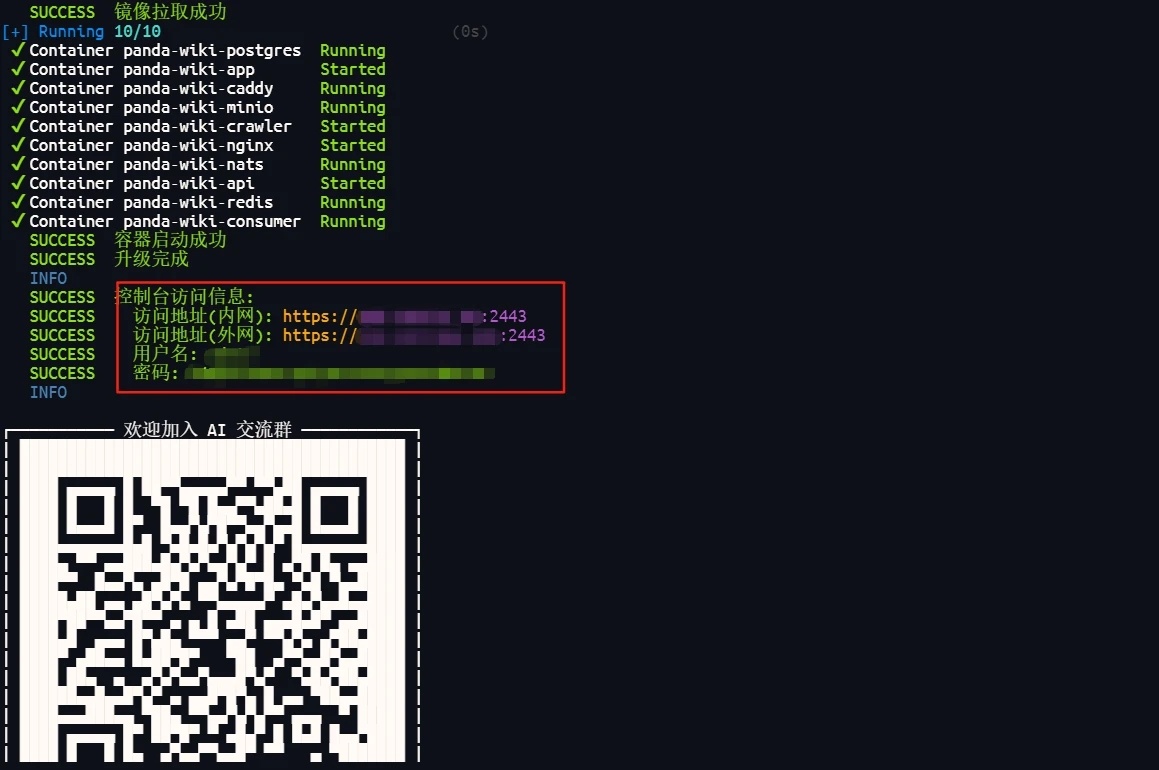
根据地址登录系统,用户名和密码再shell的框内,注意获取。
登录界面

登录界面还是比较干净清爽的。
其他界面
主界面
分析界面
设置
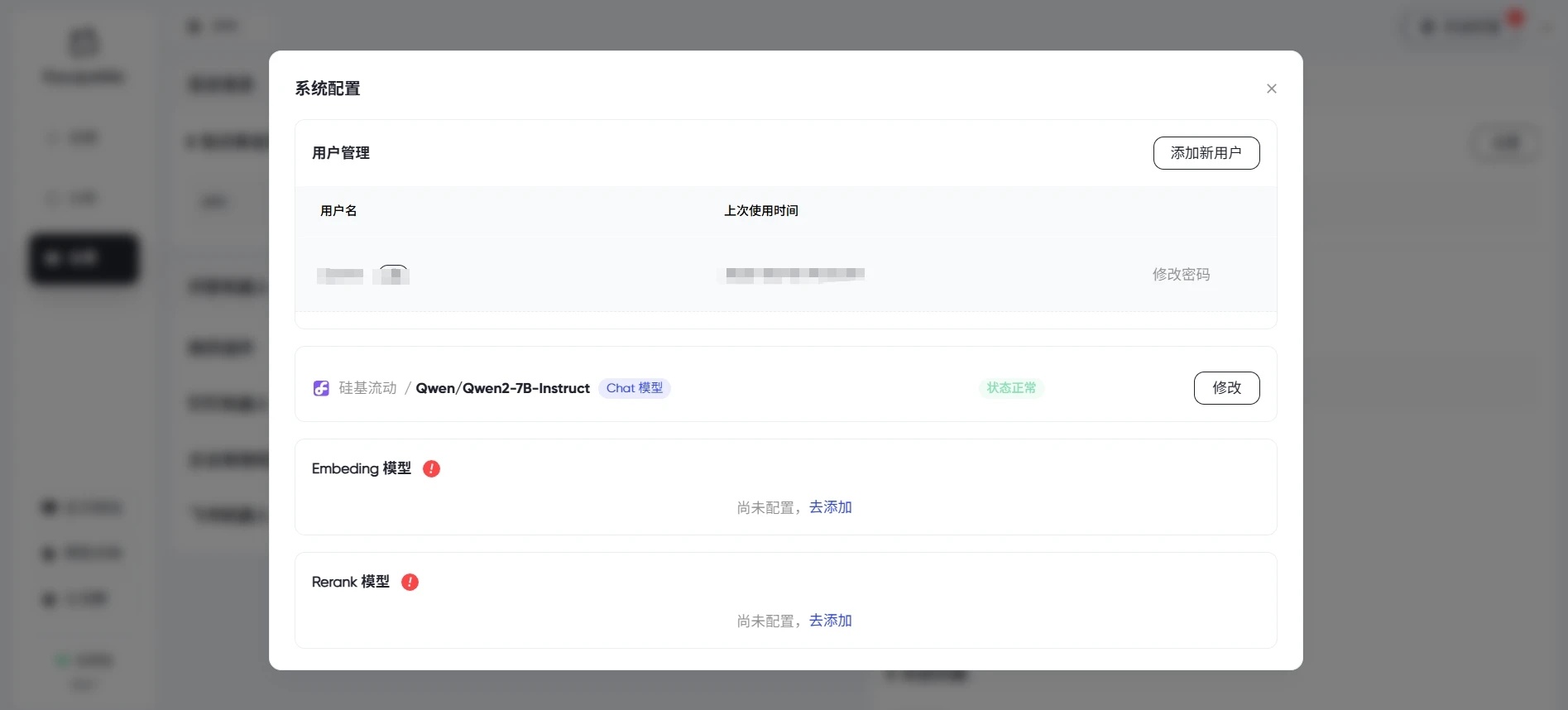
系统设置(Chat 模型是自行设置的,这里我提前设置了)
有三个模型
-
- Chat 模型:又称为 “对话模型”, 常见的 chatGPT4、Deepseek-r1、Deepseek-v3 等可以聊天的模型都属于 Chat 模型。
-
- Embeding 模型:又称为 “嵌入模型”,可以将文档转化为向量,为 PandaWiki 提供了智能搜索和内容关联的能力。
-
- Rerank 模型:又称为 “重排模型”,通过对初始结果进行二次排序,实现 “快速召回 + 精准排序”,是提升检索系统质量的关键技术。
目前 PandaWiki 可兼容的大模型供应商如下:
-
- 百智云模型广场(推荐):参考文档 百智云模型广场
-
- DeepSeek:参考文档 DeepSeek
-
- OpenAI:ChatGPT 所使用的大模型,参考文档 OpenAI
-
- Ollama:Ollama 通常是本地部署的大模型,参考文档 Ollama
-
- 硅基流动:参考文档 SiliconFlow
-
- 月之暗面:Kimi 所使用的模型,参考文档 Moonshot
-
- 其他:其他兼容 OpenAI 模型接口的 API
添加新用户
操作

点击【创建文件】,可以创建文件夹、文档或根据需要导入文档,这里选择创建【文件夹-创建文档】
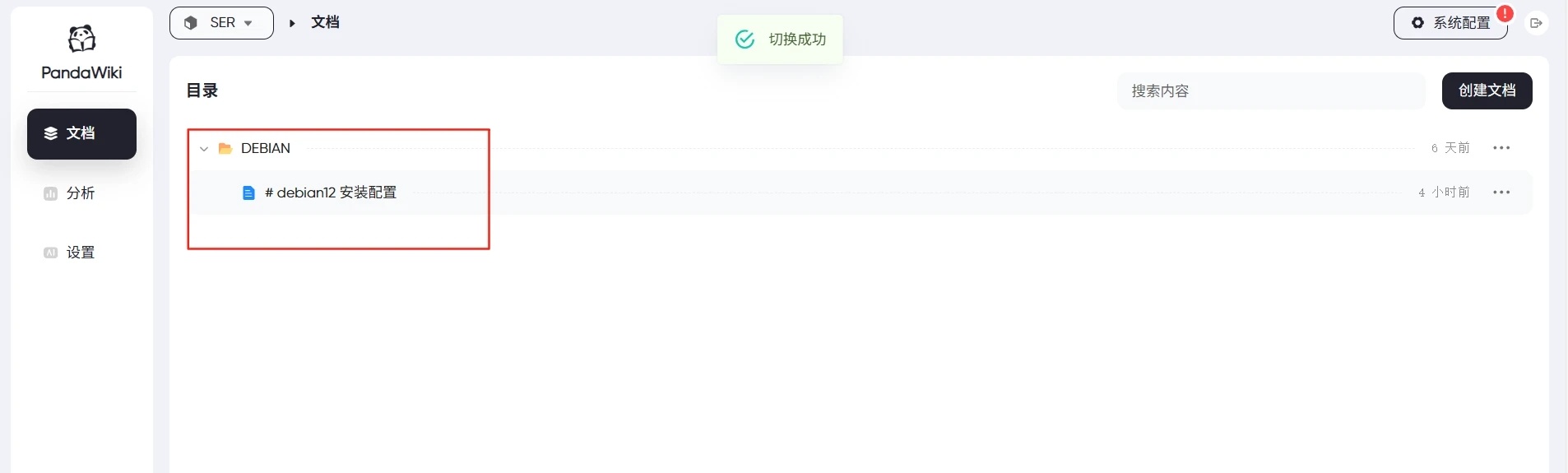
然后点击创建的文件,即可编辑
编辑界面
至此,主要的功能基本演示了,前台对外的,嗯,我这个是做的内网映射就不做演示了。
卸载 PandaWiki
使用 root 权限登录你的服务器,然后执行以下命令。
bash -c "$(curl -fsSLk https://release.baizhi.cloud/panda-wiki/manager.sh)"根据命令提示的选项,选择 “卸载”,命令执行过程将会持续几分钟,请耐心等待。
其他方面
1、PandaWiki仍处于研发快速迭代中,功能处于完善中,用于生产的话,仍需进一步考量。
2、数据导入这里还需时间,比方和思源笔记等的对接,比较数据迁移也是一个大的工作量。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...